IDE Integration¶
MLC LLM has now support for code completion on multiple IDEs. This means you can easily integrate an LLM with coding capabilities with your IDE through the MLC LLM REST API. Here we provide a step-by-step guide on how to do this.
Convert Your Model Weights¶
To run a model with MLC LLM in any platform, you need to convert your model weights to the MLC format (e.g. CodeLlama-7b-hf-q4f16_1-MLC). You can always refer to Convert Model Weights for in-depth details on how to convert your model weights. If you are using your own model weights, i.e., you finetuned the model on your personal codebase, it is important to follow these steps to convert the respective weights properly. However, it is also possible to download precompiled weights from the original models, available in the MLC format. See the full list of all precompiled weights here.
Example:
# convert model weights
mlc_llm convert_weight ./dist/models/CodeLlama-7b-hf \
--quantization q4f16_1 \
-o ./dist/CodeLlama-7b-hf-q4f16_1-MLC
Compile Your Model¶
Compiling the model architecture is the crucial step to optimize inference for a given platform. However, compilation relies on multiple settings that will impact the runtime. This configuration is specified inside the mlc-chat-config.json file, which can be generated by the gen_config command. You can learn more about the gen_config command here.
Example:
# generate mlc-chat-config.json
mlc_llm gen_config ./dist/models/CodeLlama-7b-hf \
--quantization q4f16_1 --conv-template LM \
-o ./dist/CodeLlama-7b-hf-q4f16_1-MLC
Note
Make sure to set the --conv-template flag to LM. This template is specifically tailored to perform vanilla LLM completion, generally adopted by code completion models.
After generating the MLC model configuration file, we are all set to compile and create the model library. You can learn more about the compile command here
Example:
# compile model library with specification in mlc-chat-config.json
mlc_llm compile ./dist/CodeLlama-7b-hf-q4f16_1-MLC/mlc-chat-config.json \
--device cuda -o ./dist/libs/CodeLlama-7b-hf-q4f16_1-cuda.so
For M-chip Mac:
# compile model library with specification in mlc-chat-config.json
mlc_llm compile ./dist/CodeLlama-7b-hf-q4f16_1-MLC/mlc-chat-config.json \
--device metal -o ./dist/libs/CodeLlama-7b-hf-q4f16_1-metal.so
Cross-Compiling for Intel Mac on M-chip Mac:
# compile model library with specification in mlc-chat-config.json
mlc_llm compile ./dist/CodeLlama-7b-hf-q4f16_1-MLC/mlc-chat-config.json \
--device metal:x86-64 -o ./dist/libs/CodeLlama-7b-hf-q4f16_1-metal_x86_64.dylib
For Intel Mac:
# compile model library with specification in mlc-chat-config.json
mlc_llm compile ./dist/CodeLlama-7b-hf-q4f16_1-MLC/mlc-chat-config.json \
--device metal -o ./dist/libs/CodeLlama-7b-hf-q4f16_1-metal_x86_64.dylib
For Linux:
# compile model library with specification in mlc-chat-config.json
mlc_llm compile ./dist/CodeLlama-7b-hf-q4f16_1-MLC/mlc-chat-config.json \
--device vulkan -o ./dist/libs/CodeLlama-7b-hf-q4f16_1-vulkan.so
For Windows:
# compile model library with specification in mlc-chat-config.json
mlc_llm compile ./dist/CodeLlama-7b-hf-q4f16_1-MLC/mlc-chat-config.json \
--device vulkan -o ./dist/libs/CodeLlama-7b-hf-q4f16_1-vulkan.dll
Note
The generated model library can be shared across multiple model variants, as long as the architecture and number of parameters does not change, e.g., same architecture, but different weights (your finetuned model).
Setting up the Inference Entrypoint¶
You can now locally deploy your compiled model with the MLC serve module. To find more details about the MLC LLM API visit our REST API page.
Example:
python -m mlc_llm.serve.server \
--model dist/CodeLlama-7b-hf-q4f16_1-MLC \
--model-lib ./dist/libs/CodeLlama-7b-hf-q4f16_1-cuda.so
Configure the IDE Extension¶
After deploying the LLM we can easily connect the IDE with the MLC Rest API. In this guide, we will be using the Hugging Face Code Completion extension llm-ls which has support across multiple IDEs (e.g., vscode, intellij and nvim) to connect to an external OpenAI compatible API (i.e., our MLC LLM REST API).
After installing the extension on your IDE, open the settings.json extension configuration file:

Then, make sure to replace the following settings with the respective values:
"llm.modelId": "dist/CodeLlama-7b-hf-q4f16_1-MLC"
"llm.url": "http://127.0.0.1:8000/v1/completions"
"llm.backend": "openai"
This will enable the extension to send OpenAI compatible requests to the MLC Serve API. Also, feel free to tune the API parameters. Please refer to our REST API documentation for more details about these API parameters.
"llm.requestBody": {
"best_of": 1,
"frequency_penalty": 0.0,
"presence_penalty": 0.0,
"logprobs": false,
"top_logprobs": 0,
"logit_bias": null,
"max_tokens": 128,
"seed": null,
"stop": null,
"suffix": null,
"temperature": 1.0,
"top_p": 1.0
}
The llm-ls extension supports a variety of different model code completion templates. Choose the one that best matches your model, i.e., the template with the correct tokenizer and Fill in the Middle tokens.
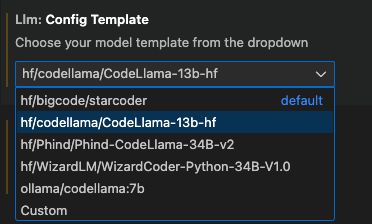
After everything is all set, the extension will be ready to use the responses from the MLC Serve API to provide off-the-shelf code completion on your IDE.
Conclusion¶
Please, let us know if you have any questions. Feel free to open an issue on the MLC LLM repo!