Quick Start¶
Examples¶
To begin with, try out MLC LLM support for int4-quantized Llama3 8B. It is recommended to have at least 6GB free VRAM to run it.
Install MLC LLM. MLC LLM is available via pip. It is always recommended to install it in an isolated conda virtual environment.
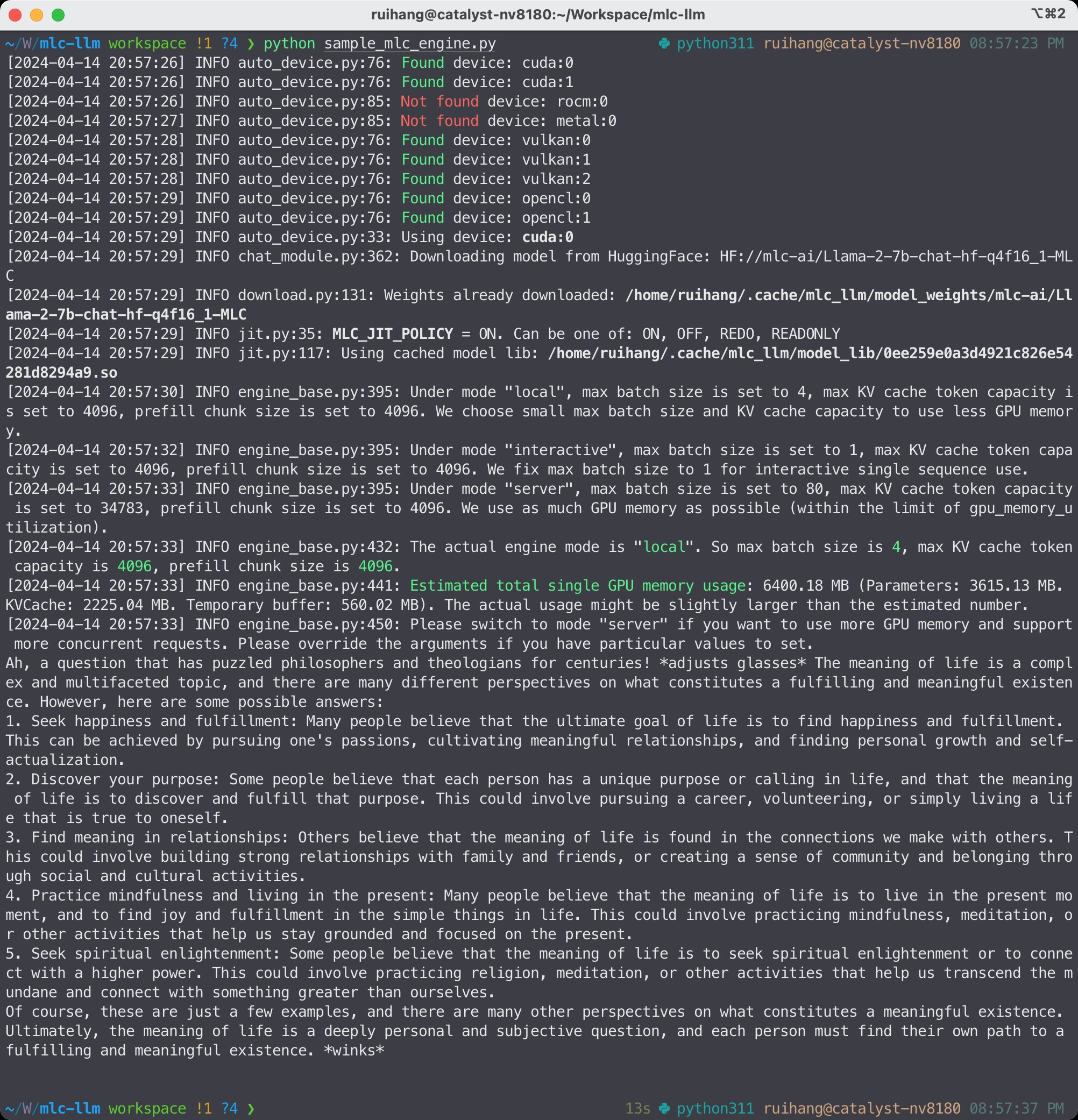
Run chat completion in Python. The following Python script showcases the Python API of MLC LLM:
from mlc_llm import MLCEngine
# Create engine
model = "HF://mlc-ai/Llama-3-8B-Instruct-q4f16_1-MLC"
engine = MLCEngine(model)
# Run chat completion in OpenAI API.
for response in engine.chat.completions.create(
messages=[{"role": "user", "content": "What is the meaning of life?"}],
model=model,
stream=True,
):
for choice in response.choices:
print(choice.delta.content, end="", flush=True)
print("\n")
engine.terminate()
Documentation and tutorial. Python API reference and its tutorials are available online.
MLC LLM Python API¶
Install MLC LLM. MLC LLM is available via pip. It is always recommended to install it in an isolated conda virtual environment.
Launch a REST server. Run the following command from command line to launch a REST server at http://127.0.0.1:8000.
mlc_llm serve HF://mlc-ai/Llama-3-8B-Instruct-q4f16_1-MLC
Send requests to server. When the server is ready (showing INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)),
open a new shell and send a request via the following command:
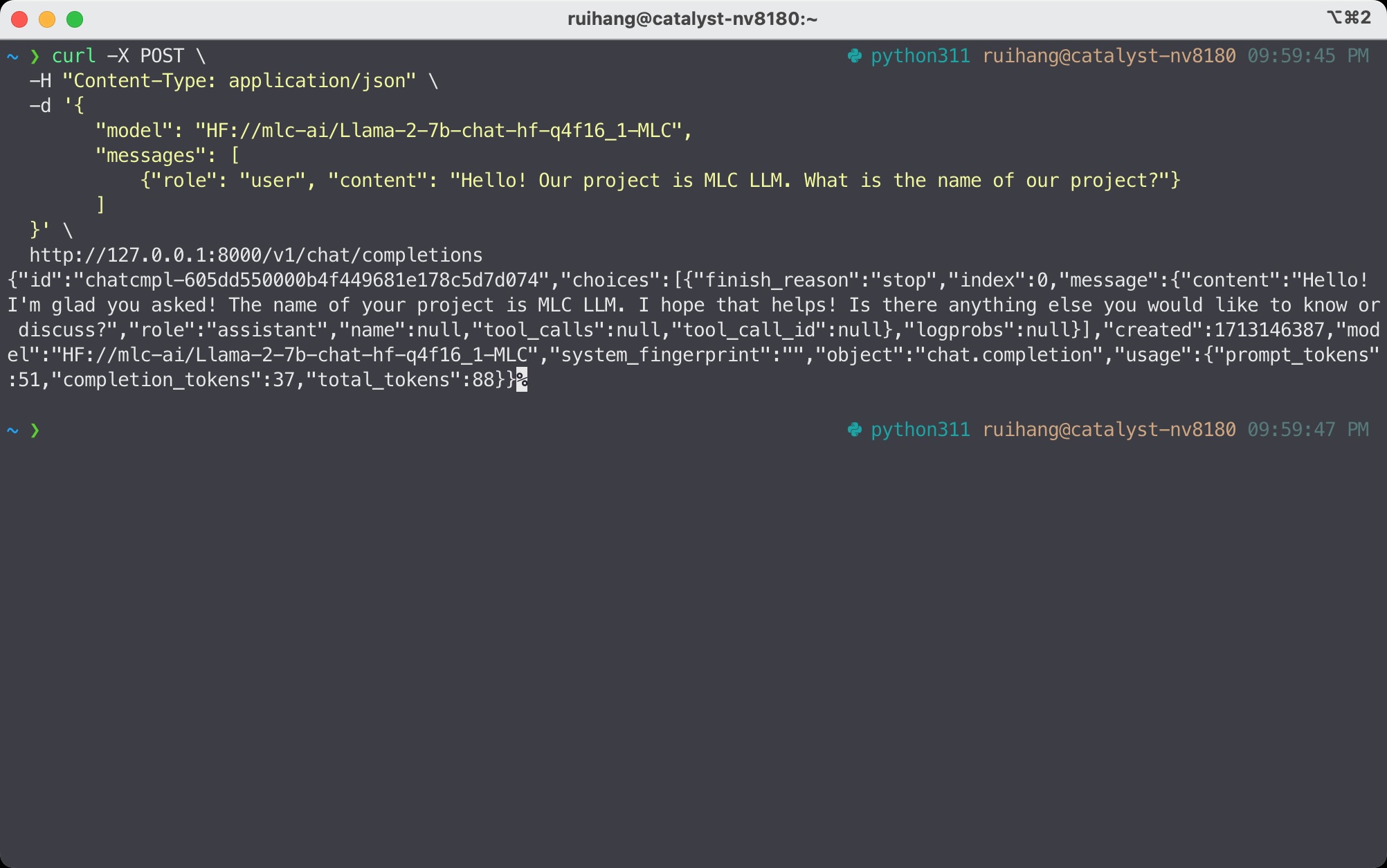
curl -X POST \
-H "Content-Type: application/json" \
-d '{
"model": "HF://mlc-ai/Llama-3-8B-Instruct-q4f16_1-MLC",
"messages": [
{"role": "user", "content": "Hello! Our project is MLC LLM. What is the name of our project?"}
]
}' \
http://127.0.0.1:8000/v1/chat/completions
Documentation and tutorial. Check out REST API for the REST API reference and tutorial. Our REST API has complete OpenAI API support.
Send HTTP request to REST server in MLC LLM¶
Install MLC LLM. MLC LLM is available via pip. It is always recommended to install it in an isolated conda virtual environment.
For Windows/Linux users, make sure to have latest Vulkan driver installed.
Run in command line.
mlc_llm chat HF://mlc-ai/Llama-3-8B-Instruct-q4f16_1-MLC
If you are using windows/linux/steamdeck and would like to use vulkan, we recommend installing necessary vulkan loader dependency via conda to avoid vulkan not found issues.
conda install -c conda-forge gcc libvulkan-loader
WebLLM. MLC LLM generates performant code for WebGPU and WebAssembly, so that LLMs can be run locally in a web browser without server resources.
Download pre-quantized weights. This step is self-contained in WebLLM.
Download pre-compiled model library. WebLLM automatically downloads WebGPU code to execute.
Check browser compatibility. The latest Google Chrome provides WebGPU runtime and WebGPU Report as a useful tool to verify WebGPU capabilities of your browser.
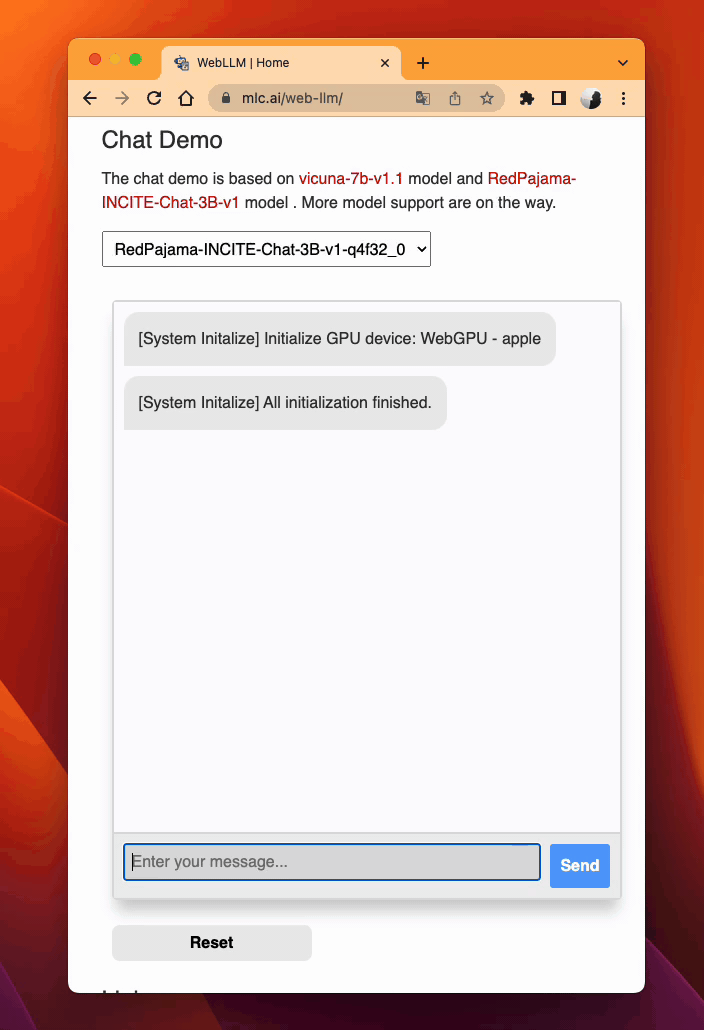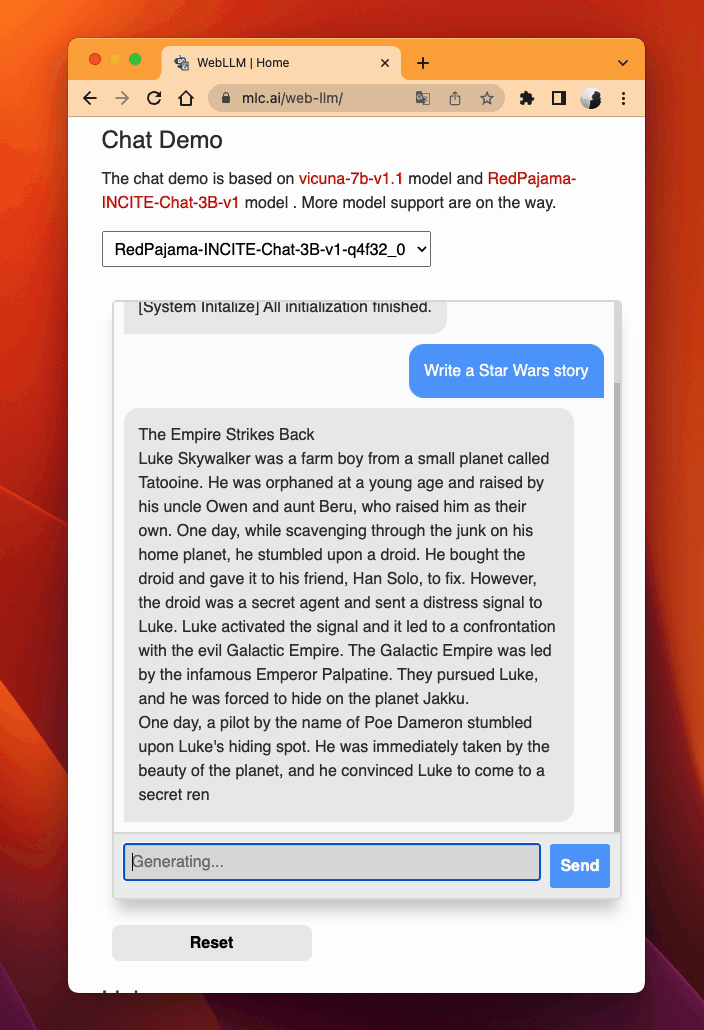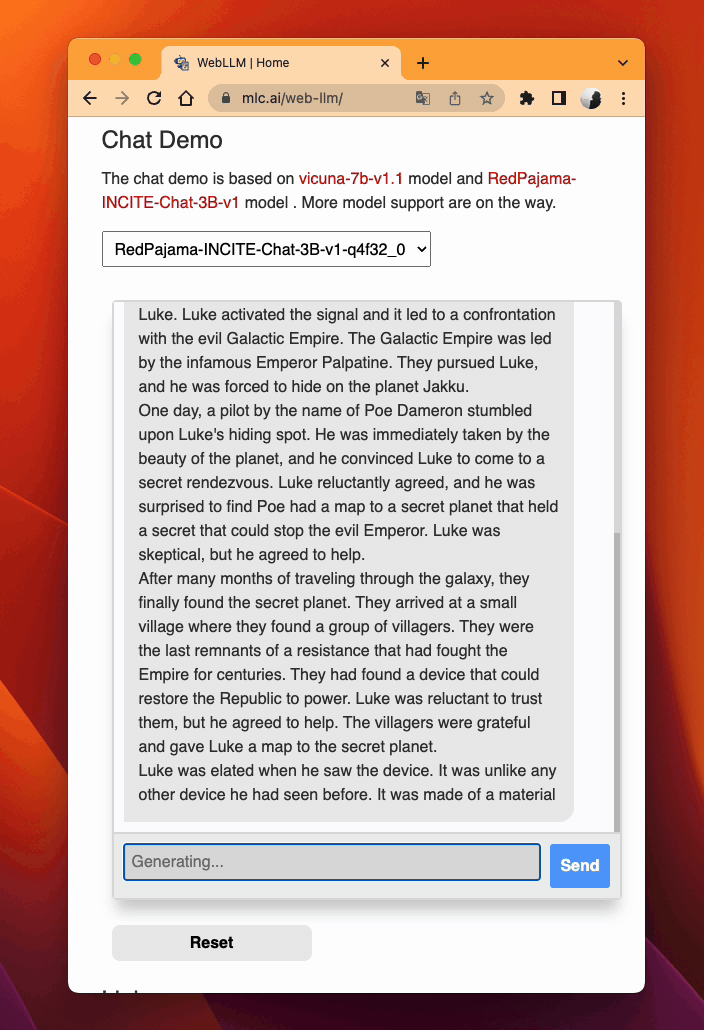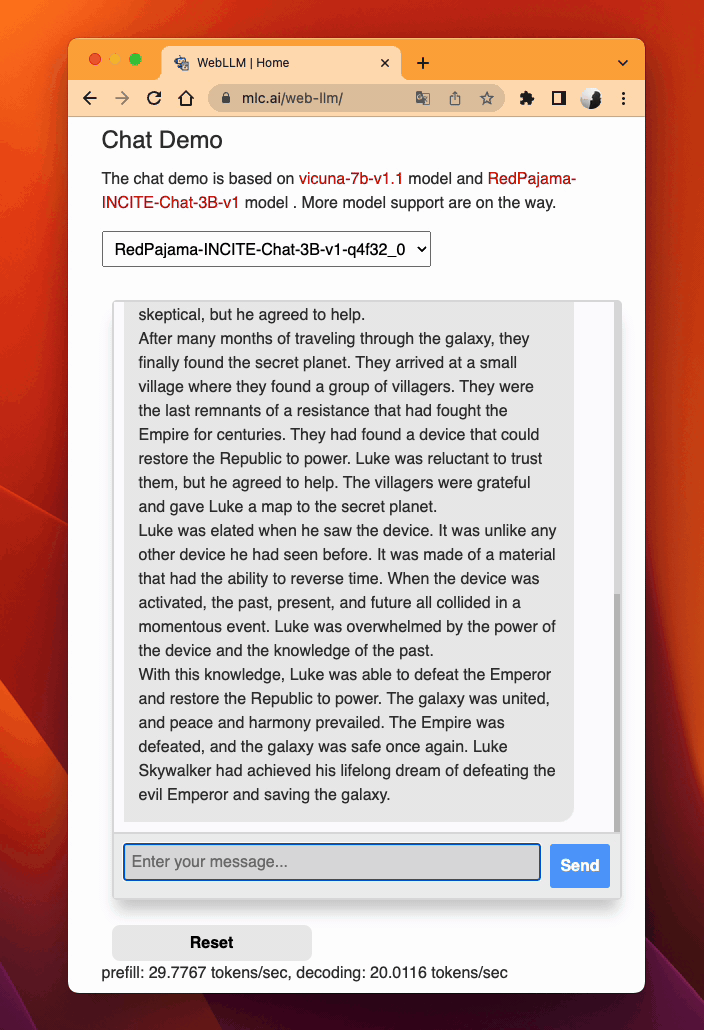
MLC LLM on Web¶
Install MLC Chat iOS. It is available on AppStore:

Note. The larger model might take more VRAM, try start with smaller models first.
Tutorial and source code. The source code of the iOS app is fully open source, and a tutorial is included in documentation.
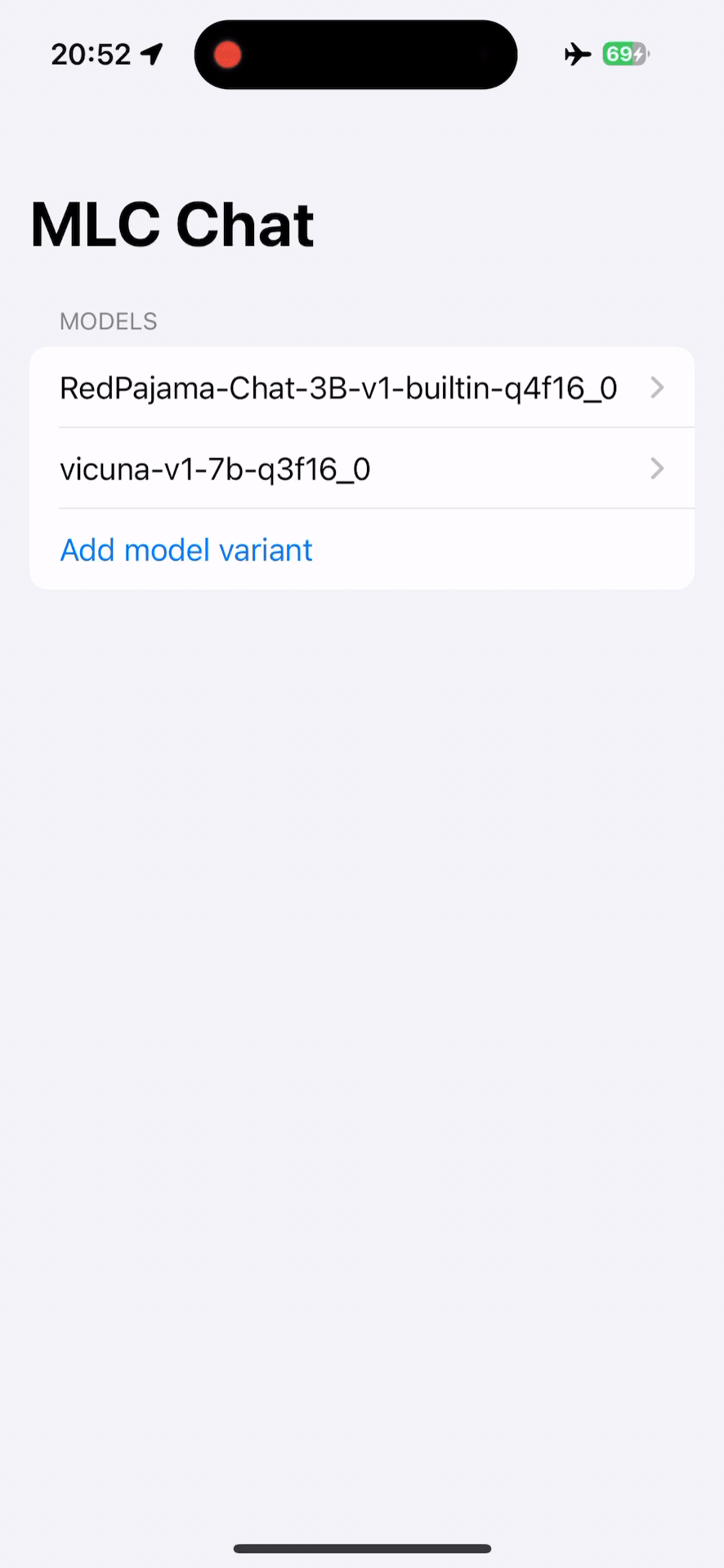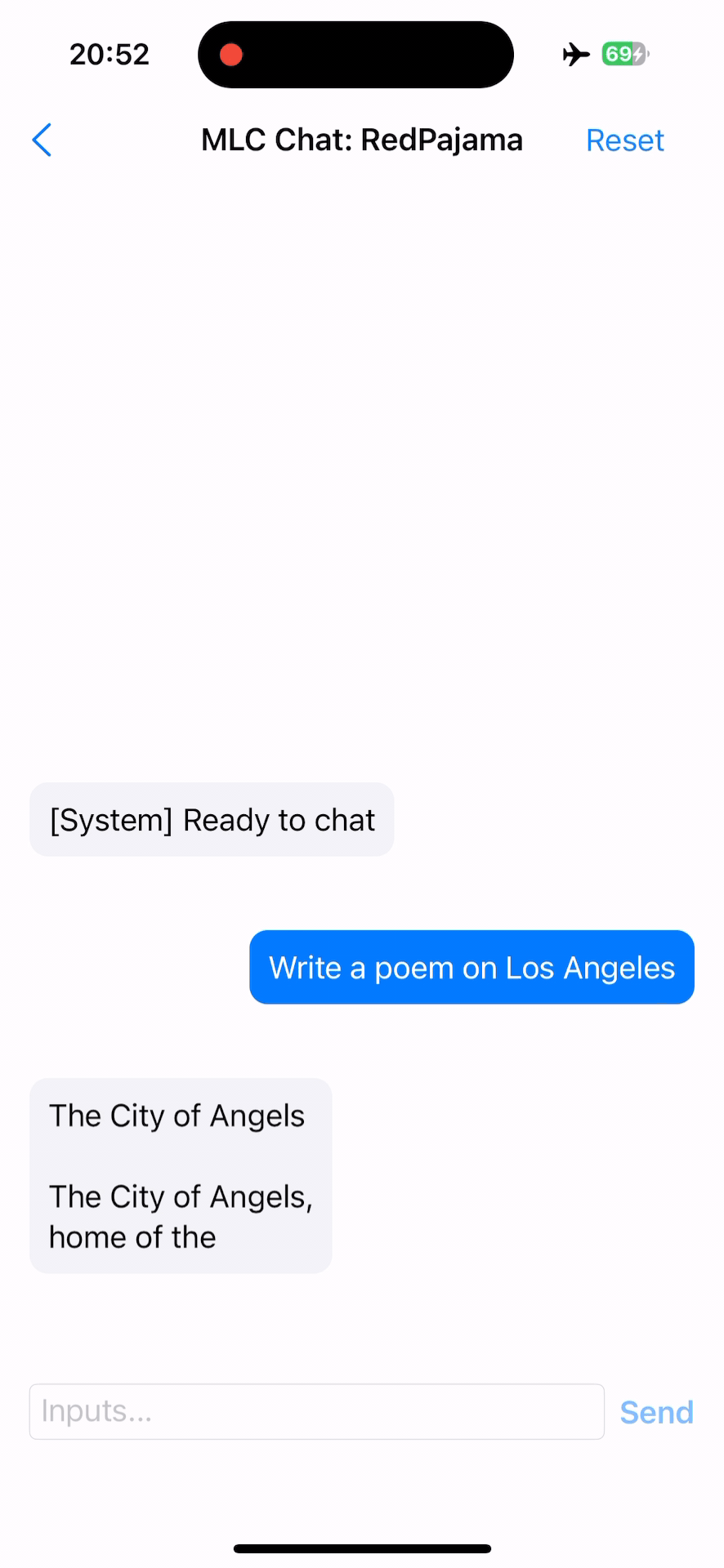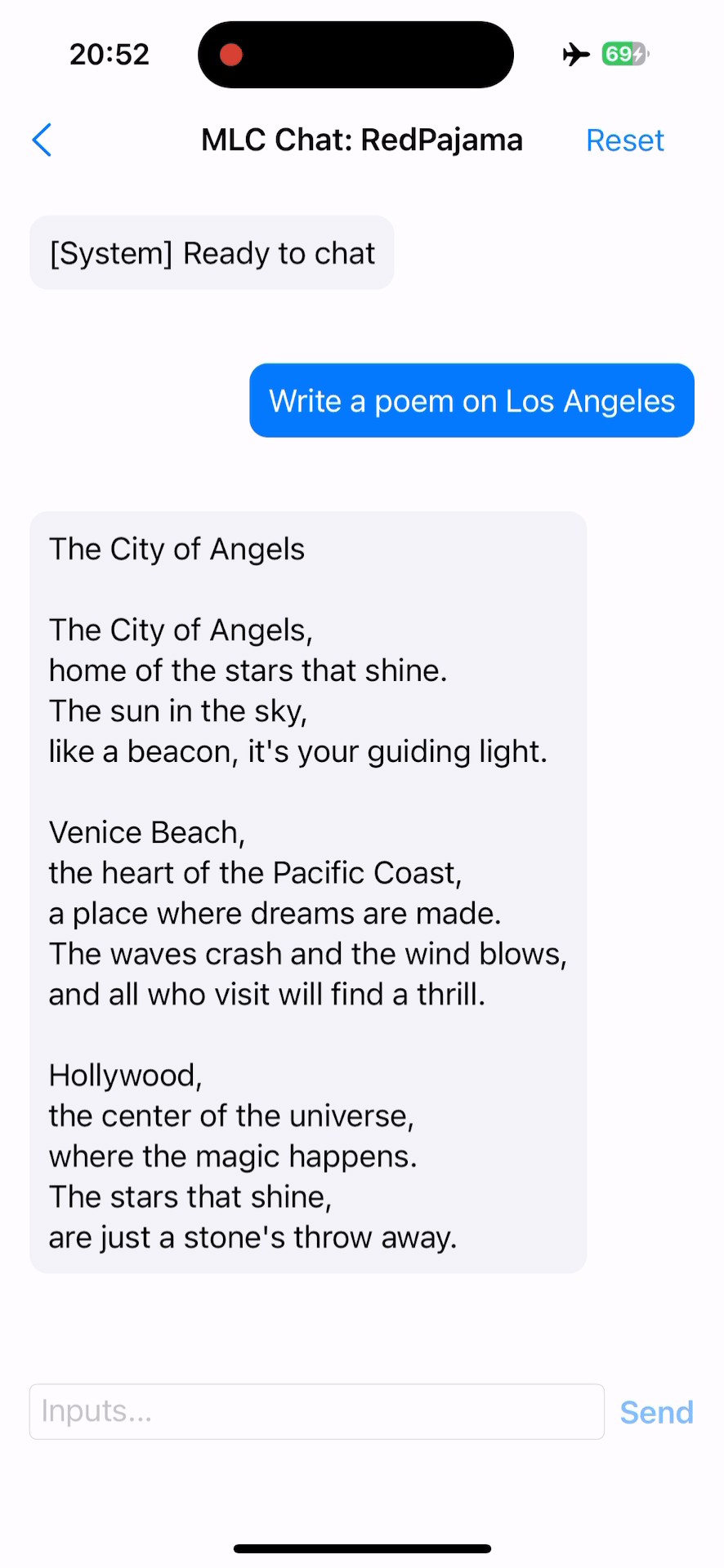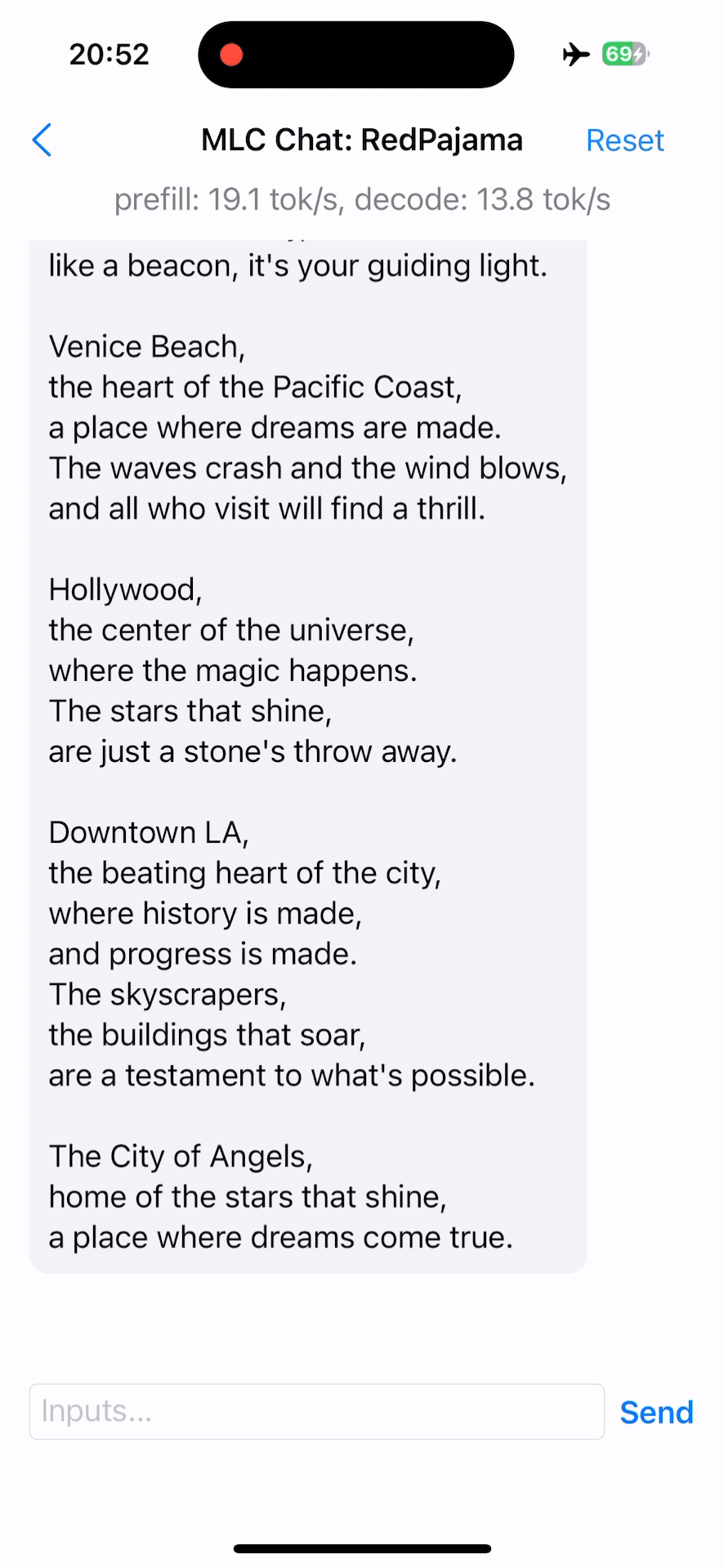
MLC Chat on iOS¶
Install MLC Chat Android. A prebuilt is available as an APK:
Note. The larger model might take more VRAM, try start with smaller models first. The demo is tested on
Samsung S23 with Snapdragon 8 Gen 2 chip
Redmi Note 12 Pro with Snapdragon 685
Google Pixel phones
Tutorial and source code. The source code of the android app is fully open source, and a tutorial is included in documentation.
MLC LLM on Android¶
What to Do Next¶
Check out Introduction to MLC LLM for the introduction of a complete workflow in MLC LLM.
Depending on your use case, check out our API documentation and tutorial pages:
Convert Model Weights, if you want to run your own models.
Compile Model Libraries, if you want to deploy to web/iOS/Android or control the model optimizations.
Report any problem or ask any question: open new issues in our GitHub repo.